Stop Words and Tokenization with NLTK: Natural Language Processing (NLP) is a sub-area of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (native) languages. This is nothing but how to program computers to process and analyze large amounts of natural language data.
NLP = Computer Science + AI + Computational Linguistics
In another way, Natural language processing is the capability of computer software to understand human language as it is spoken. NLP is one of the component of artificial intelligence (AI).
About Natural Language Processing Tool Kit
- The Natural Language Toolkit, or more commonly is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language.
- It was developed by Steven Bird and Edward Loper in the Department of Computer and Information Science at the University of Pennsylvania.
- A software package for manipulating linguistic data and performing NLP tasks.
- Natural Language Processing Tool Kit is intended to support research and teaching in NLP or closely related areas, including empirical linguistics, cognitive science, artificial intelligence, information retrieval, and machine learning
- It supports classification, tokenization, stemming, tagging, parsing, and semantic reasoning functionalities.
- It includes more than 50 corpora and lexical sources such as the Penn Treebank Corpus, Open Multilingual Wordnet, Problem Report Corpus, and Lin’s Dependency Thesaurus.
Following table shows the important modules in Natural Language Processing Tool Kit :
| Language Processing Task | NLTK-modules | Functionality |
| Accessing corpora | nltk.corpus | Standardized interfaces to corpora and lexicons |
| String processing | nltk.tokenize, nltk.stem | Tokenizers, sentence tokenizers, stemmers |
| Collocation discovery | nltk.collocations | t-test, chi-squared, point-wise mutual information |
| Classification | nltk.classify, nltk.cluster | Decision tree, maximum entropy, naive Bayes, EM, k-means |
| Chunking | nltk.chunk | Regular expression, n-gram, named entity |
| Part-of-speech tagging | nltk.tag | n-gram, backoff, Brill, HMM, TnT |
| Parsing | nltk.parse | Chart, feature-based, unification, probabilistic, dependency |
| Semantic interpretation | nltk.sem, nltk.inference | Lambda calculus, first-order logic, model checking |
| Evaluation metrics | nltk.metrics | Precision, recall, agreement coefficients |
| Probability and estimation | nltk.probability | Frequency distributions, smoothed probability distributions |
| Applications | nltk.app, nltk.chat | Graphical concordancer, parsers, WordNet browser, chatbots |
The goal of designing the Natural Language Processing Tool Kit are as follows,
Simplicity:
It provides an in-built framework along with substantial building blocks, giving users a practical knowledge of NLP without getting bogged down in the tedious house-keeping usually associated with processing annotated language data
Consistency:
To provide a uniform framework with consistent interfaces and data structures, and easily guessable method names
To provide a structure into which new software modules can be easily accommodated,including alternative implementations and competing approaches to the same task
Modularity:
To provide components that can be used independently without needing to understand
the rest of the toolkit
NLTK-Installation and Requirements
NLTK requires Python versions 2.7, 3.4, 3.5, or 3.6
NLTK-Library included in ANACONDA
On Windows or Linux or Mac, you can install NLTK using pip command. It can be directly installed using pip in terminal using the following command
>>> pip install nltk
You can directly Install from http://pypi.python.org/pypi/nltk
Step 1:
Open Command Prompt and type python
Step 2:
After a successful installation, we will go for importing-NLTK.
The NLTK-package is then included using the following command
>>>import nltk
Step 3:
Next, we need to install some of the packages or components for Natural Language Processing Tool Kit. For that Open command prompt or anaconda prompt then type,
>>>nltk.download( )
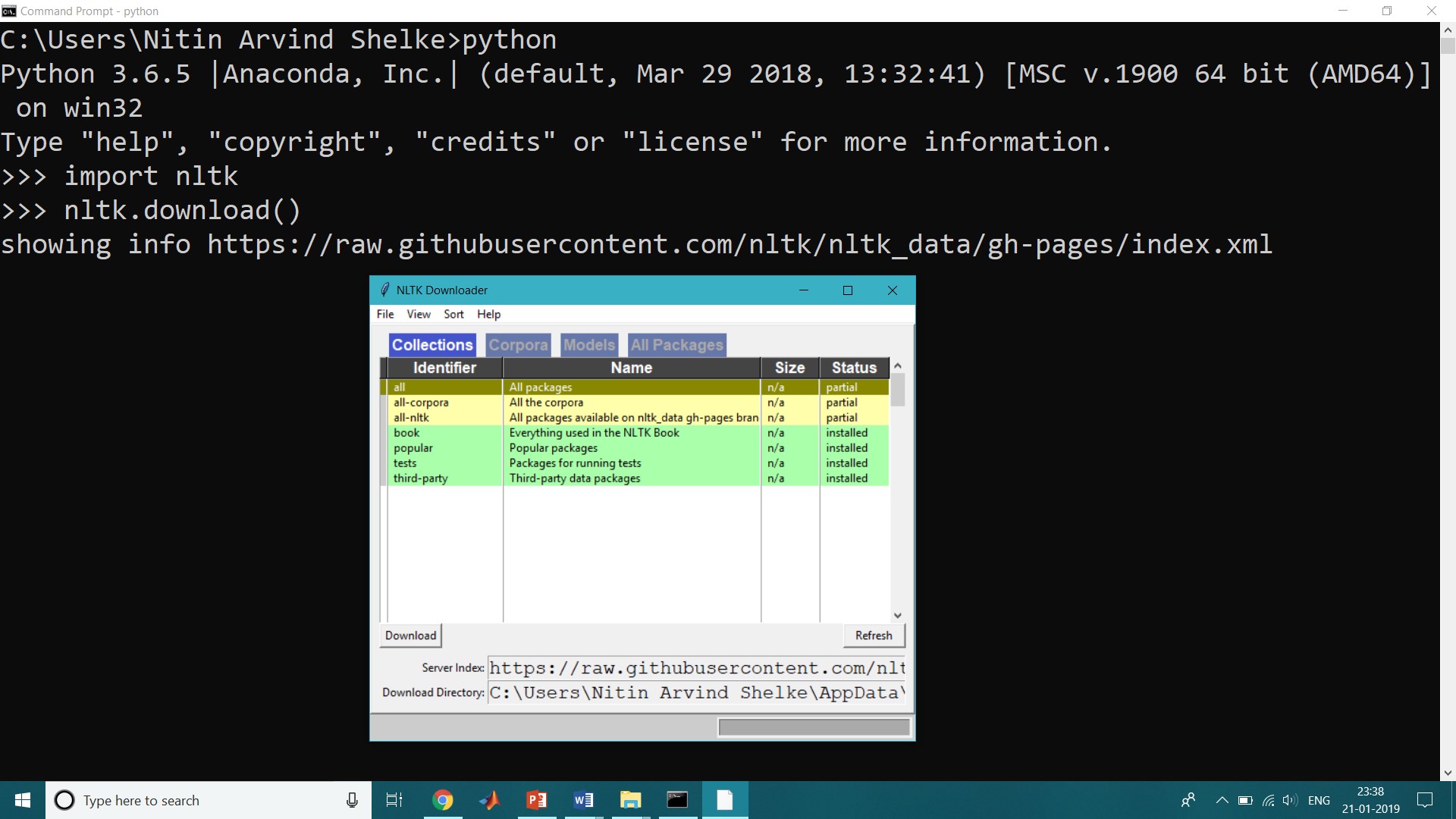
After typing nltk.download() we will get NLTK-downloader window through which we can download all the package needed for further processing in Natural Language Processing Tool Kit.
The process of converting data to something a computer can understand is referred to as pre-processing. One of the primary forms of pre-processing is to filter out useless data. In natural language processing, useless words (data), are referred to as stop words.
There is also a corpus of stop words, that is, high-frequency of words like “the, to and also” that we sometimes want to filter out of a document before further processing.
A stop word is a commonly used word such as “the”, “a”, “an”, “in” that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query.
Stop words usually have little lexical content, and their presence in a text fails to distinguish it from other texts.
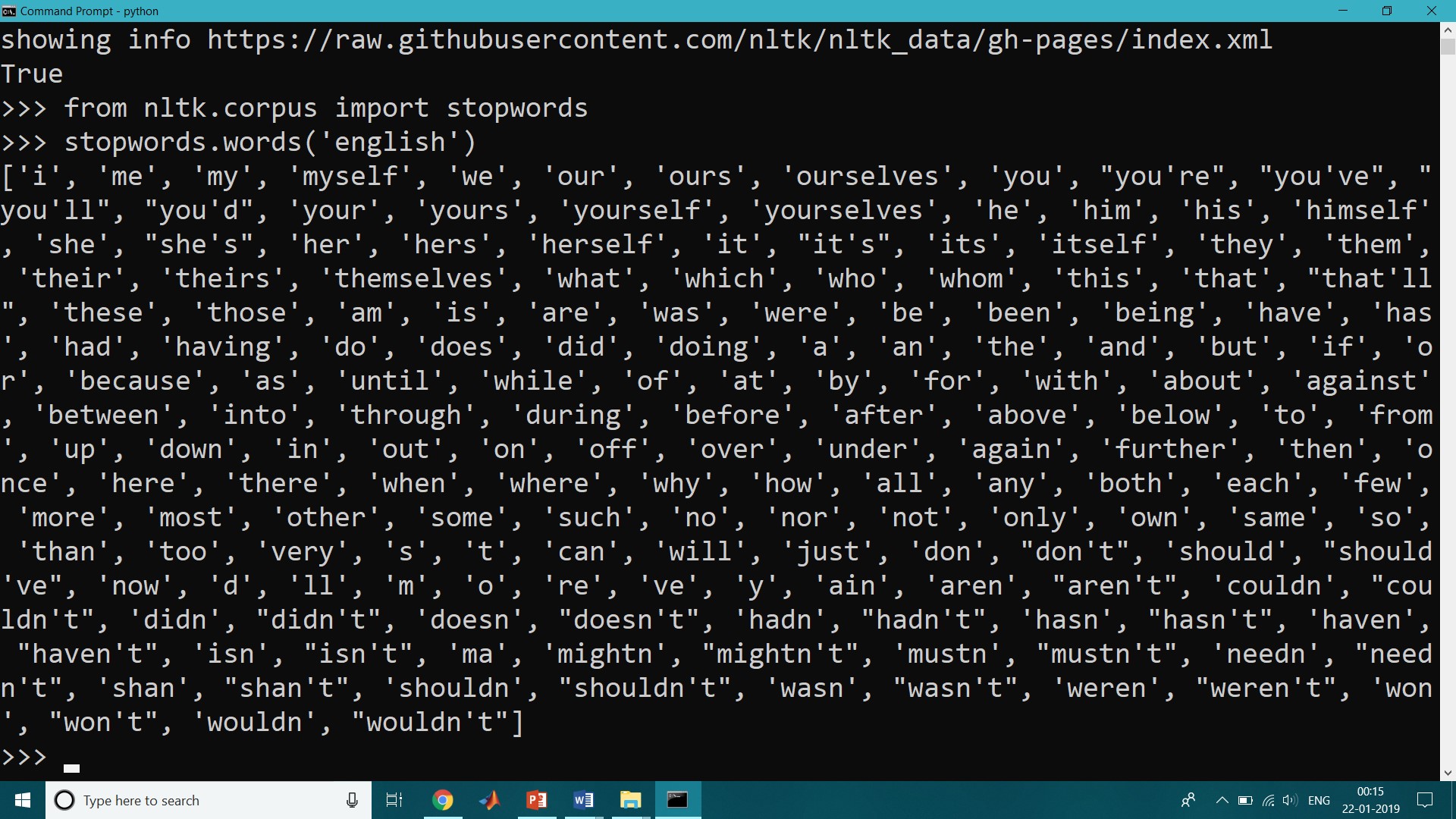
>>> import nltk
>>> from nltk.corpus import stopwords
>>> stopwords.words(‘english’)
Program for Removing the stop words with NLTK:
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = “This is a sample sentence, showing off the stop words filtration.”
stop_words = set(stopwords.words(‘english’))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
Output:
[‘This’, ‘is’, ‘a’, ‘sample’, ‘sentence’, ‘,’, ‘showing’,
‘off’, ‘the’, ‘stop’, ‘words’, ‘filtration’, ‘.’]
[‘This’, ‘sample’, ‘sentence’, ‘,’, ‘showing’, ‘stop’,
‘words’, ‘filtration’, ‘.’]
Tokenization is the process by dividing the quantity of text into smaller parts called tokens.
Alternatively, Tokenization is the process of breaking up the given text into units called tokens. The tokens may be words or number or punctuation mark. Tokenization does this task by locating word boundaries. Ending point of a word and beginning of the next word is called word boundaries.
These tokens are very useful for finding such patterns as well as is considered as a base step for stemming and lemmatization.
Given a character sequence and a defined document unit, tokenization is the task of chopping it up into pieces, called tokens, perhaps at the same time throwing away certain characters, such as punctuation. Here is an example of tokenization:
Sent1: – Hello Friends, Welcome to the world of Natural Language Processing
Word Token in Sent1 are as follows
‘Hello’ ‘Friends’ ‘,’ ‘Welcome’ ‘to’ ‘the’ ‘world’ ‘of’ ‘Natural’ ‘Language’ ‘Processing’
Total Number of Tokens: – 11
There are two ways of tokenization in Natural Language Processing Tool Kit, one is sentence tokenization, and another is word tokenization
Code for Sentence Tokenization:
Following is the code for Sentence Tokenization
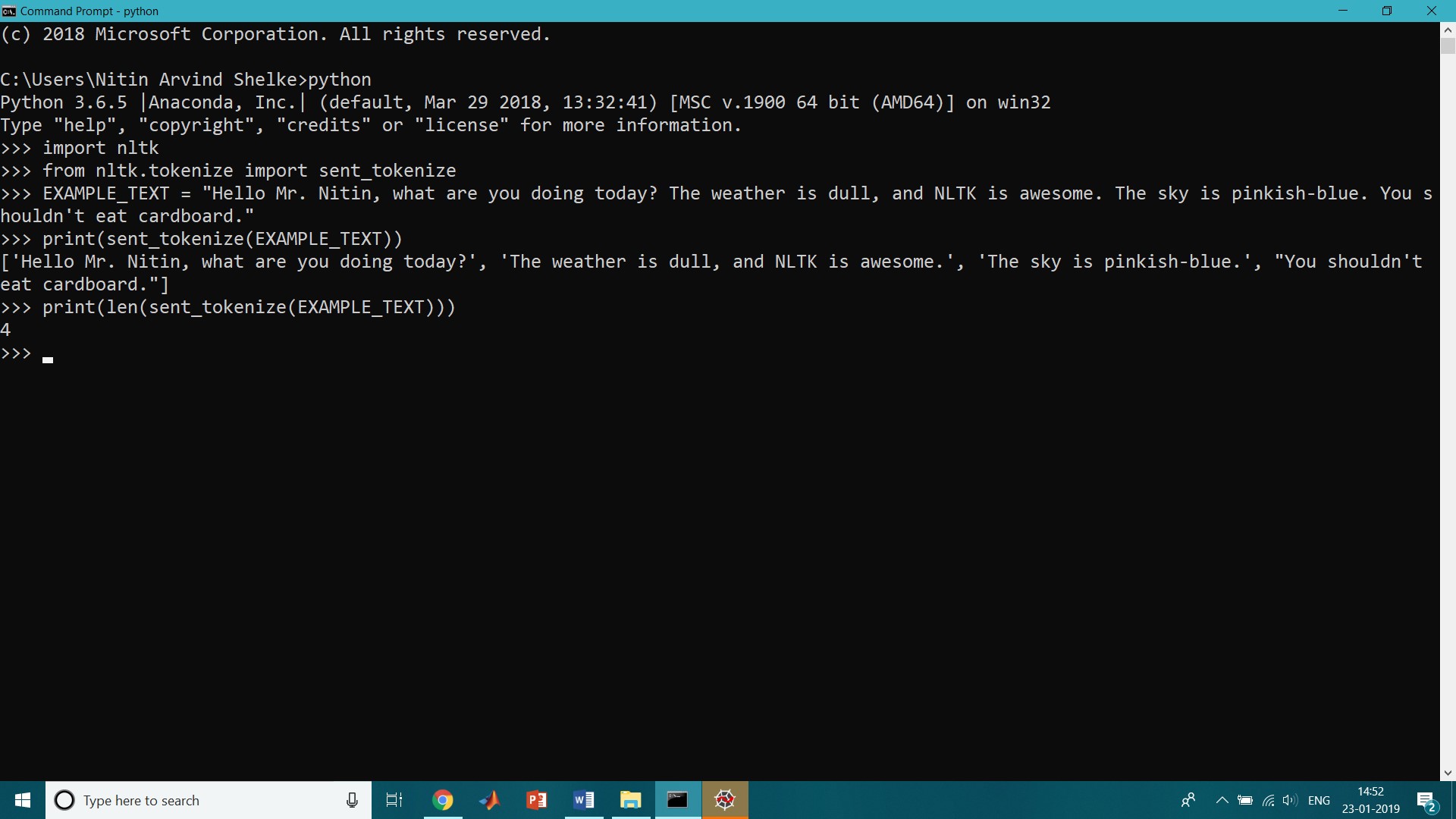
>>import nltk
>>from nltk.tokenize import sent_tokenize
>> EXAMPLE_TEXT = “Hello Mr. Nitin, what are you doing today? The weather is dull, and NLTK is awesome. The sky is pinkish-blue. You shouldn’t eat cardboard.”
>>print(sent_tokenize(EXAMPLE_TEXT))
>>print(len(sent_tokenize(EXAMPLE_TEXT)))
Output
[‘Hello Mr. Nitin, what are you doing today?’, ‘The weather is dull, and NLTK is awesome.’, ‘The sky is pinkish-blue.’, “You shouldn’t eat cardboard.”]
4
Code for Word Tokenization:
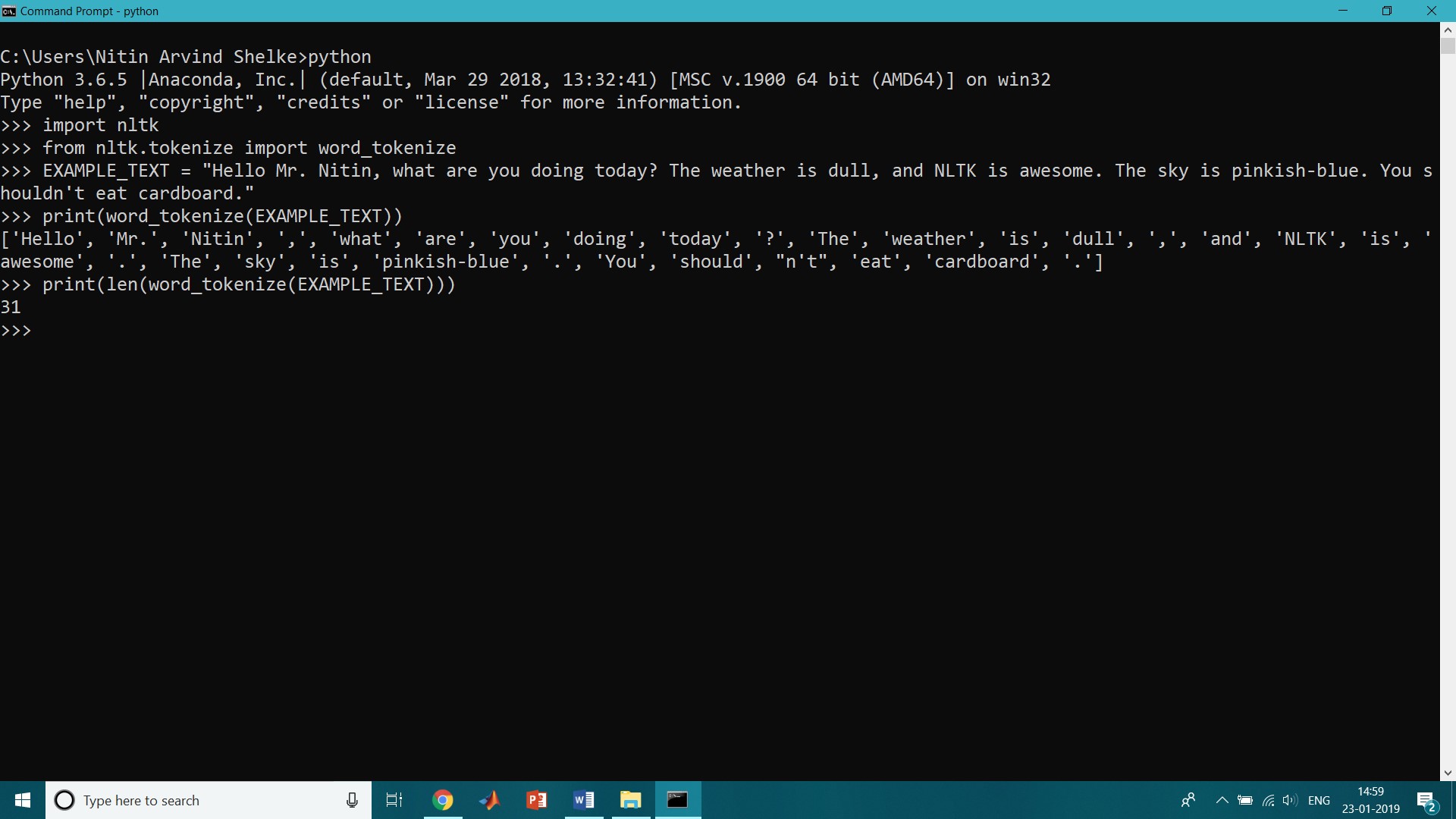
Following is the code for word tokenization,
>>import nltk
>>from nltk.tokenize import word_tokenize
>> EXAMPLE_TEXT = “Hello Mr. Nitin, what are you doing today? The weather is dull, and NLTK is awesome. The sky is pinkish-blue. You shouldn’t eat cardboard.”
>>print(word_tokenize(EXAMPLE_TEXT))
>>print(len(word_tokenize(EXAMPLE_TEXT)))
OUTPUT
[‘Hello’, ‘Mr.’, ‘Smith’, ‘,’, ‘how’, ‘are’, ‘you’, ‘doing’, ‘today’, ‘?’, ‘The’, ‘weather’, ‘is’, ‘great’, ‘,’, ‘and’, ‘Python’, ‘is’, ‘awesome’, ‘.’, ‘The’, ‘sky’, ‘is’, ‘pinkish-blue’, ‘.’, ‘You’, ‘should’, “n’t”, ‘eat’, ‘cardboard’, ‘.’]