

What is Big Data? What size of Data is considered to be big and will be termed as Big Data? We have many relative assumptions for the term Big Data. It is possible that, the amount of data say 50 terabytes can be considered as Big Data for Start-up’s but it may not be Big Data for the companies like Google and Facebook. It is because they have infrastructure to store and process this vast amount of data.
When data itself becomes big is Big Data.
What is this Apache Hadoop and Apache Spark? What made IT professional to talk about these buzz words and why the demand for Data Analytics and Data Scientists are growing exponentially?
Apache Hadoop and Apache Spark are both Big Data frameworks – they provide some of the most popular tools used to carry out common Big Data-related tasks.
Understanding Hadoop:
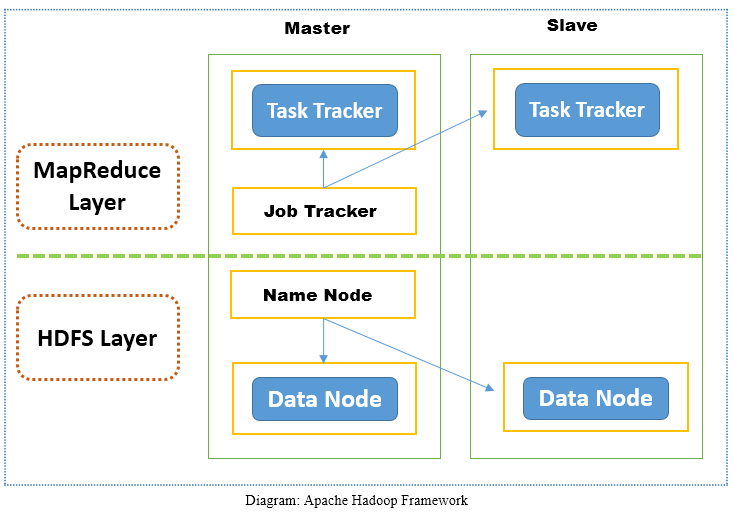
Apache Hadoop is an open-source software framework designed to scale up from single servers to thousands of machines and run applications on clusters of commodity hardware. Apache Hadoop does a lot of things really well. It has been evolving and gradually maturing with new features and capabilities to make it easier to setup and use. There is a large ecosystem of applications that now leverage Hadoop. Apache Hadoop framework is divided into two layers. First layer is storage layer and known as Hadoop Distributed File System (HDFS) while second layer is the processing layer and known as MapReduce. Storage layer of Hadoop i.e. HDFS is responsible for storing data while MapReduce is responsible for processing data in Hadoop Cluster.
Understanding Apache Spark:
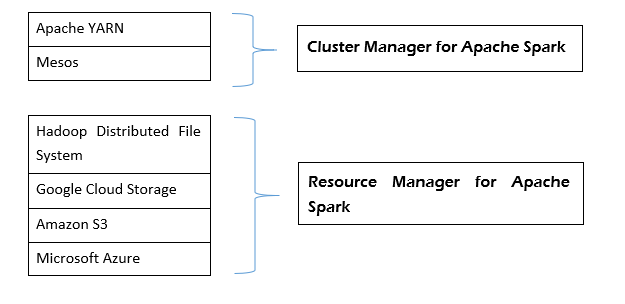
Apache Spark is a lightning-fast and cluster computing technology framework, designed for fast computation on large-scale data processing. Apache Spark is a distributed processing engine but it does not come with inbuilt cluster resource manager and distributed storage system. You have to plug in a cluster manager and storage system of your choice.
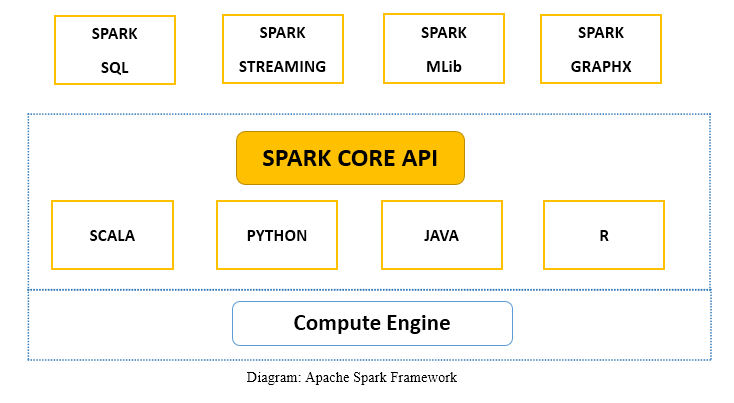
Apache Spark framework consists of Spark Core and Set of libraries. Spark core executes and manages our job by providing seamless experience to the end user. User have to submit job to Spark core and Spark core takes care of further processing, executing and reply back to the user. We have Spark Core API in different scripting languages such as Scala, Python, Java and R.
Apache Spark is data processing engine for batch and streaming modes featuring SQL queries, Graph Processing and Machine Learning.
Features:
1.Data Processing:
Apache Hadoop only processes batch data while Apache Spark process batch data as well as real time data processing. Apache Hadoop is slower than Apache Spark because if input output disk latency.
2.Compatibility:
Apache Hadoop is majorly compatible with all the data sources and file formats while Apache Spark can integrate with all data sources and file formats supported by Hadoop cluster.
3.Language Support:
Apache Hadoop supports Primary Language is Java but languages like C, C++, ruby, Python, Perl, Groovy is also supported using Hadoop Streaming While Apache Spark Supports Java, Scala, Python and R.
4.Real-time Analysis:
Apache Hadoop MapReduce fails when it comes to real-time data processing as it was designed to perform batch processing on voluminous amounts of data While Apache Spark can process real time data i.e. data coming from the real-time event streams at the rate of millions of events per second, e.g. Twitter data for instance or Facebook sharing/posting. Spark’s strength is the ability to process live streams efficiently.
Although both the tools are used for processing Big Data. Let’s take an example, Apache Spark can be used to process fraud detection while doing banking transactions. It is because, all the online payments are done in real time and we need to stop fraud transaction while ongoing process of payment while we can use Apache Hadoop for batch processing job like analysing different parameters like age-group, location, time spend of some specific YouTube videos for last 24 hrs. Or last 7 days.
When to use Apache Hadoop:
- Batch Processing of large Dataset
- No intermediate Solution required
When to use Apache Spark:
- Fast and interactive data processing
- Graph processing
- Joining Datasets
- Iterative jobs
- Real time processing
- Machine Learning
Apache Hadoop offers a web interface for submitting and executing jobs. All the Business Intelligence (BI) tools like Qlikview, Tableau, Zoom Data, Zeeplin have connectivity with Hadoop and its ecosystem. It means you can store data in HDFS and after post processing of data, using Hadoop tools, you can directly visualize your output that runs on storage system.
Apache Spark is data execution framework based on Hadoop HDFS. Apache Spark is not replacement to Hadoop but it is an application framework. Apache Spark is new but gaining more popularity than Apache Hadoop because of Real time and Batch processing capabilities.
Apache-Hadoop-vs-Apache-Spark Conclusion:
Apache Hadoop and Apache Spark both are the most important tool for processing Big Data. They both have equally specific weightage in Information Technology domain. Any developer can choose between Apache Hadoop and Apache Spark based on their project requirement and ease of handling.
Apache Hadoop and Apache Spark tool depends on business needs that should determine the choice of a framework. Linear processing of huge datasets is the advantage of Hadoop MapReduce, while Spark delivers fast performance, iterative processing, real-time analytics, graph processing, machine learning and more. The great news is the Spark is fully compatible with the Hadoop eco-system and works smoothly with Hadoop Distributed File System, Apache Hive, etc.
If you are working on Real time environment and fast processing, you must choose Apache Spark. The truth is that Apache Spark and Apache Hadoop have a symbiotic relationship with each other. Apache Hadoop provides features that Apache Spark does not possess such as distributed file system.
Apache Hadoop is a more mature platform for batch processing. You can integrate large number of products with Apache Hadoop. Even if Apache Spark is more powerful but the facts is that – you still need HDFS to store all the data, If you want to use other Hadoop components like Hive, Pig, Impala, Hbase , Sqoop or other projects. This concludes, you will still need to run Hadoop and MapReduce alongside Apache Spark to utilise all the resources of Big Data Package.




