Pig Case Study :
Problem Statement: To build a script which produces a report listing each Company & State and number of complaints raised by them.
We have a data set of complaints (incidents or trouble tickets) of a software system raised by different companies.
The details of the fields (i.e. data dictionary) of each record is in below format:
Date received = dtr:chararray,
Product = prd:chararray,
Sub-product = sprd:chararray,
Issue = iss:chararray,
Sub-issue = siss:chararray,
Company public response = pubrsp:chararray,
Company = cmpny:chararray,
State = stt:chararray,
ZIP Code = zip:chararray,
TAG = tag:chararray,
Consumer consent provided = consent:chararray,
Submitted via = via:chararray,
Date sent to company = dts:chararray,
Company response to consumer = conrsp:chararray,
Timely response = tmly:chararray,
Consumer disputed = dsput:chararray,
Complaint ID = cmpid:int
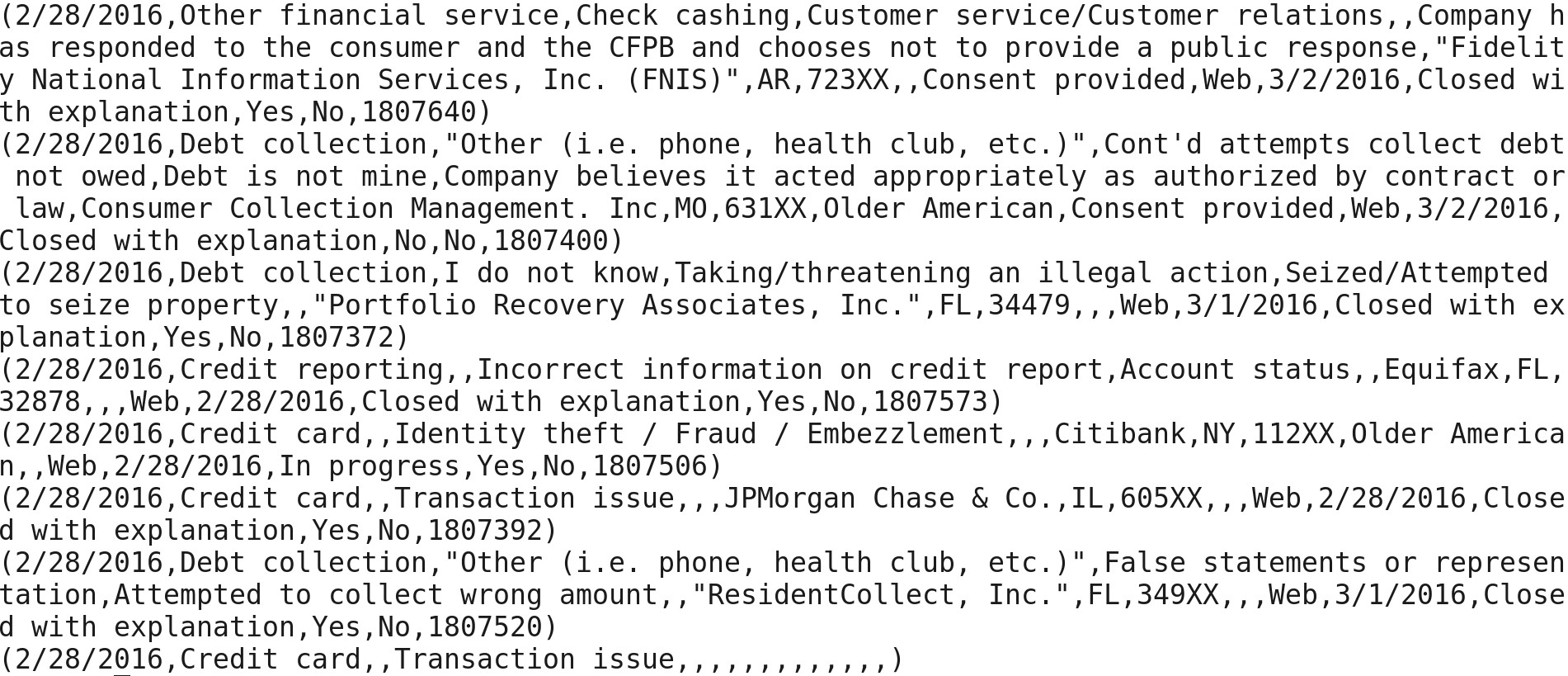
Sample data-set:
4/1/2016|Debt collection|”Other (i.e. phone, health club, etc.)”|Disclosure verification of debt|Not given enough info to verify debt||”Convergent Resources, Inc.”|IL|60035|||Web|4/1/2016|Closed with explanation|Yes|No|1859891
4/1/2016|Consumer Loan|Vehicle loan|Managing the loan or lease|||Ally Financial Inc.|TX|779XX|||Web|4/1/2016|In progress|Yes|No|1861161
4/1/2016|Bank account or service|Savings account|”Account opening, closing, or management”|||Ally Financial Inc.|TN|381XX|||Web|4/1/2016|In progress|Yes|No|1861175
I am working on single distributed node cluster and data is located at /home/rahul/data and name of file is ccd-200-pid.txt

Since, I am working on Pig distributed mode, I will make sure Hadoop Cluster is UP. I am going to copy data to HDFS location. I am creating pigdata directory at HDFS location and copying data to this location.
Command to create directory: hadoop fs –mkdir pigdata
Command to copy data from local directory to HDFS location: Hadoop fs –copyFromLocal <source> <destination>
Hadoop fs –copyFromLocal ccd-200-pipe.txt /user/rahul/pigdata/

Command to list file at HDFS location: Hadoop fs –ls <hdfs directory location>
Hadoop fs –ls /user/rahul/pigdata

Now, I will open pig terminal.

My data is located in HDFS location at /user/rahul/pigdata
In Pig, we have alias concept. It means we have to use new alias at every step. We need to process every time with the alias only.
I am storing data of file name ccd-200-pipe.txt into alias inputdata. We can have any name of the alias. I am executing below codes as per below data schema.
inputdata = LOAD ‘/user/rahul/pigdata/ccd-200-pipe.txt’ USING PigStorage(‘|’) AS (dtr:chararray, prd:chararray, sprd:chararray, iss:chararray, siss:chararray, pubrsp:chararray, cmpny:chararray, stt:chararray, zip:chararray, tag:chararray, consent:chararray, via:chararray, dts:chararray, conrsp:chararray, tmly:chararray, dsput:chararray, cmpid:int);

Pig offers you dump and store comamnd to trigger your executions. I am going to check successful execution of load command using dump command.

Below is output on screen and we can see that data is loaded successfully into alias inputdata
Now I am using Filter Command to filter null complain id into the dataset.
Command: fltd1 = FILTER inputdata BY cmpid IS NOT NULL;
![]()
Below is output on screen and we can see that data is loaded successfully into alias fltd1;

Now, I am using SUBSTRING function to filter out data and Month and assigning data type. I am assigning date and month into new column.
trd1 = FOREACH fltd1 GENERATE cmpid, prd, cmpny, stt, SUBSTRING(dtr,5,9), SUBSTRING(dtr,0,1);
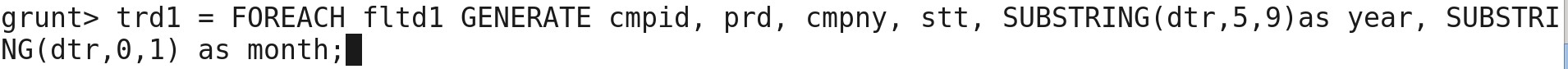
We can use describe function to check schema of alias and datatype.

I am assigning data type to date and month for the new column.
trd1 = FOREACH fltd1 GENERATE cmpid, prd, cmpny, stt, SUBSTRING(dtr,5,9)as year, SUBSTRING(dtr,0,1) as month;

I am grouping alias trd1 based on company and state.
grd1 = GROUP trd1 BY (cmpny, stt);

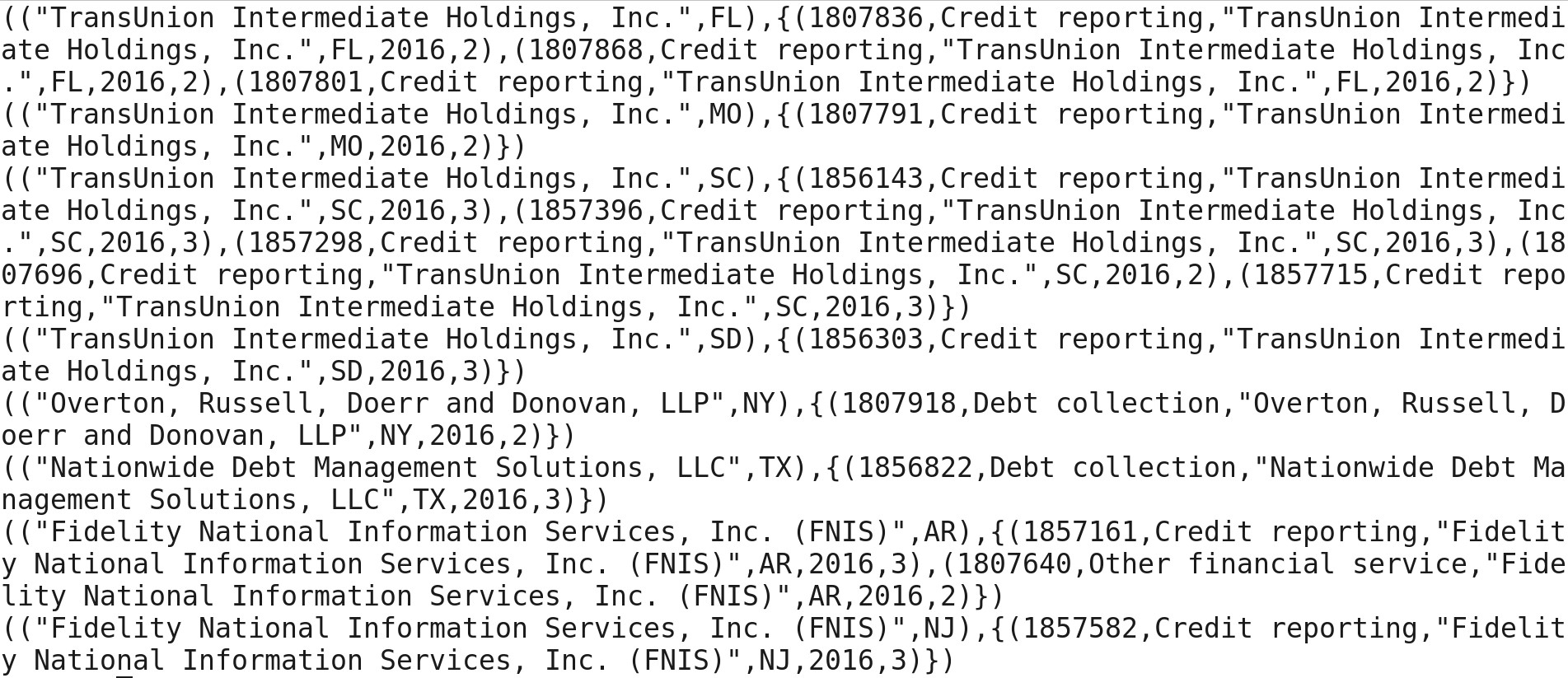
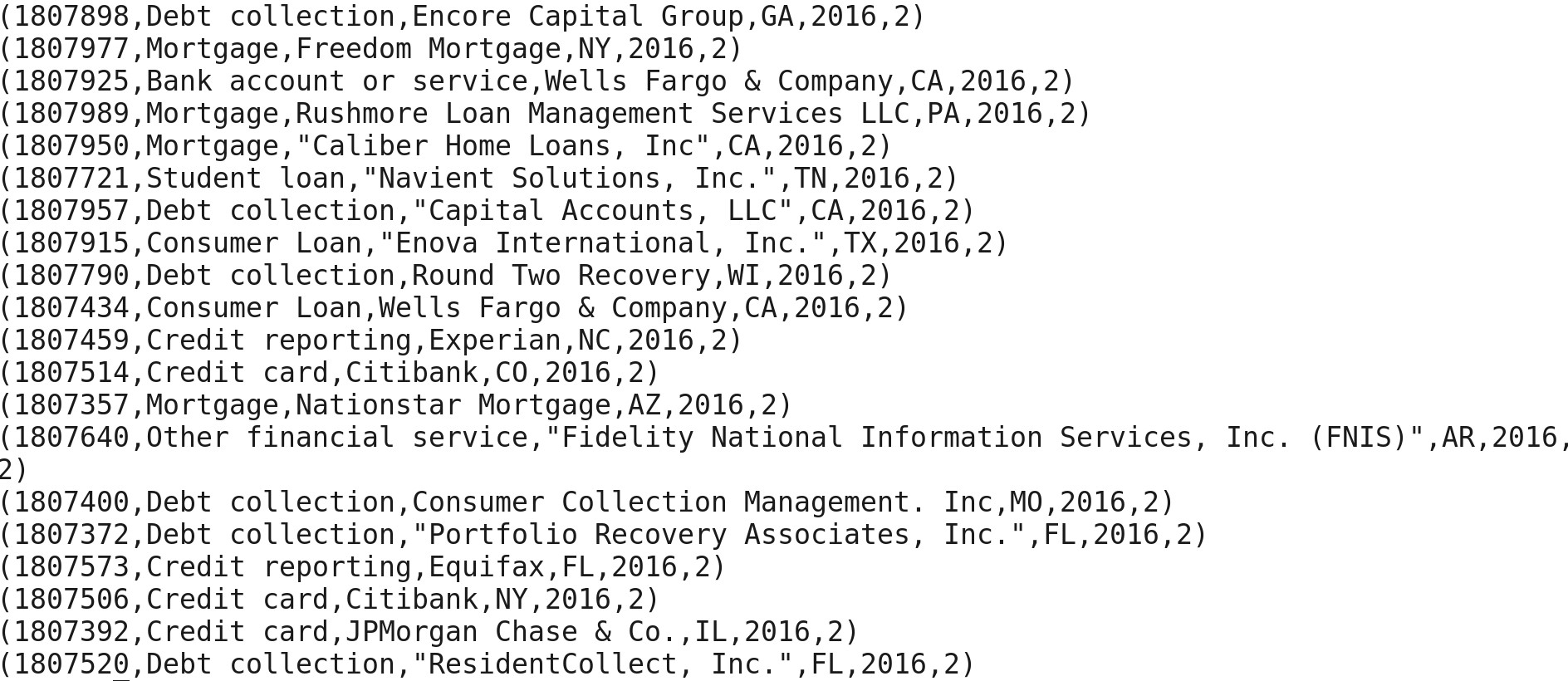
Now, I am counting alias trd1 based on grouping.
aggrd1 = FOREACH grd1 GENERATE group, COUNT(trd1);

Dump aggrd1;

Now, I am counting the total number of complains and getting output in descending order.
srtd1 = ORDER aggrd1 BY $1 DESC;
![]()
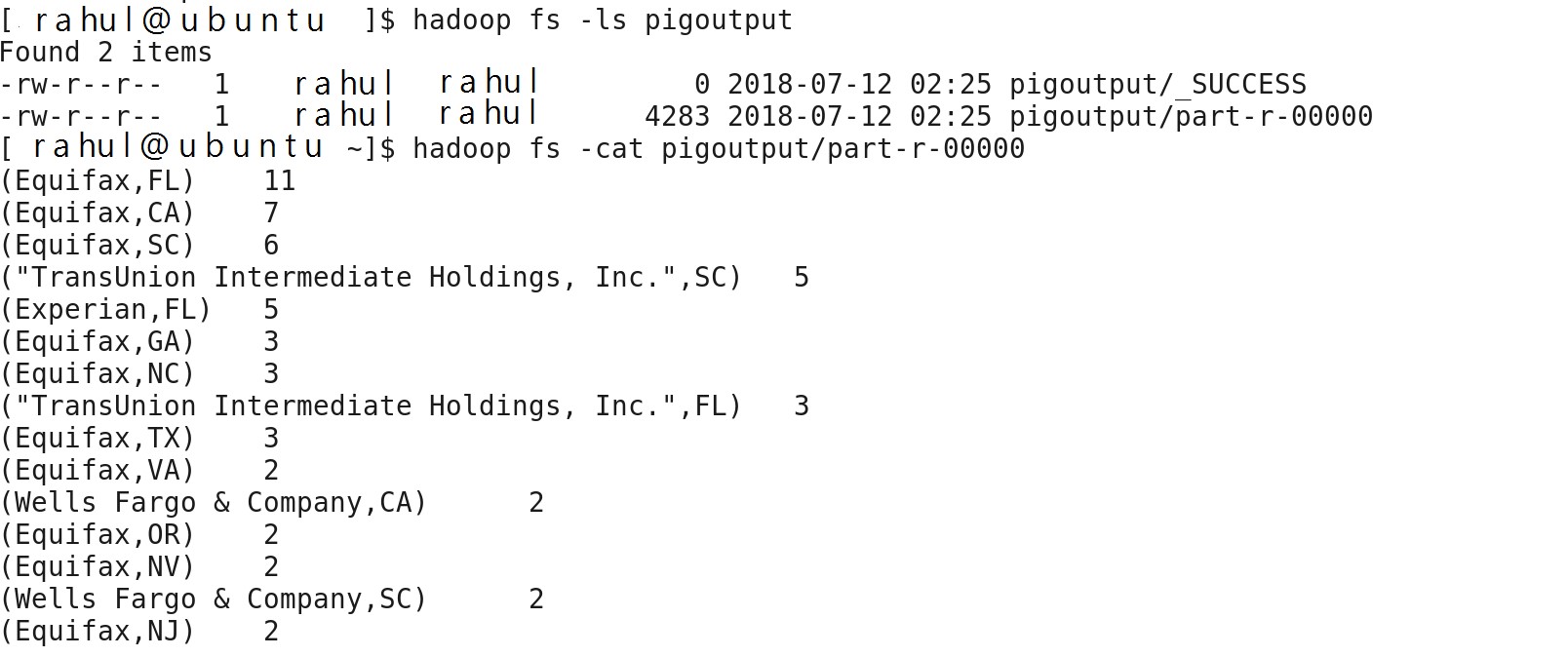
I am getting below output by using command Dump srtd1;

I got the expected output i.e. Number of tickets raised by different company along with the state. I am storing the final output into HDFS for BI processing.
STORE srtd1 INTO ‘pigoutput’ ;
Now I can check using HDFS command – new directory being created at HDFS location.
hadoop fs –ls pigoutput
We can see success file and part-r-00000 files created inside pigoutput directory. Actual content is present on filename part-r-00000