Named Entity Recognition with NLTK : Natural language processing is a sub-area of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (native) languages. This is nothing but how to program computers to process and analyse large amounts of natural language data.
NLP = Computer Science + AI + Computational Linguistics
In another way, Natural language processing is the capability of computer software to understand human language as it is spoken. NLP is one of the component of artificial intelligence (AI).
About NLTK
- The Natural Language Toolkit, or more commonly NLTK, is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language.
- It was developed by Steven Bird and Edward Loper in the Department of Computer and Information Science at the University of Pennsylvania.
- A software package for manipulating linguistic data and performing NLP tasks.
Named Entity Recognition (NER)
Named Entity Recognition is used in many fields in Natural Language Processing (NLP), and it can help answering many real-world questions.
Named entity recognition(NER) is probably the first step towards information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
Information comes in many shapes and sizes.
One important form is structured data, where there is a regular and predictable organization of entities and relationships.
For example, we might be interested in the relation between companies and locations.
Given a company, we would like to be able to identify the locations where it does business; conversely, given a location, we would like to discover which companies do business in that location. Our data is in tabular form, then answering these queries is straightforward.
| Org Name | Location Name |
| TCS | PUNE |
| INFOCEPT | PUNE |
| WIPRO | PUNE |
| AMAZON | HYDERABAD |
| INTEL | HYDERABAD |
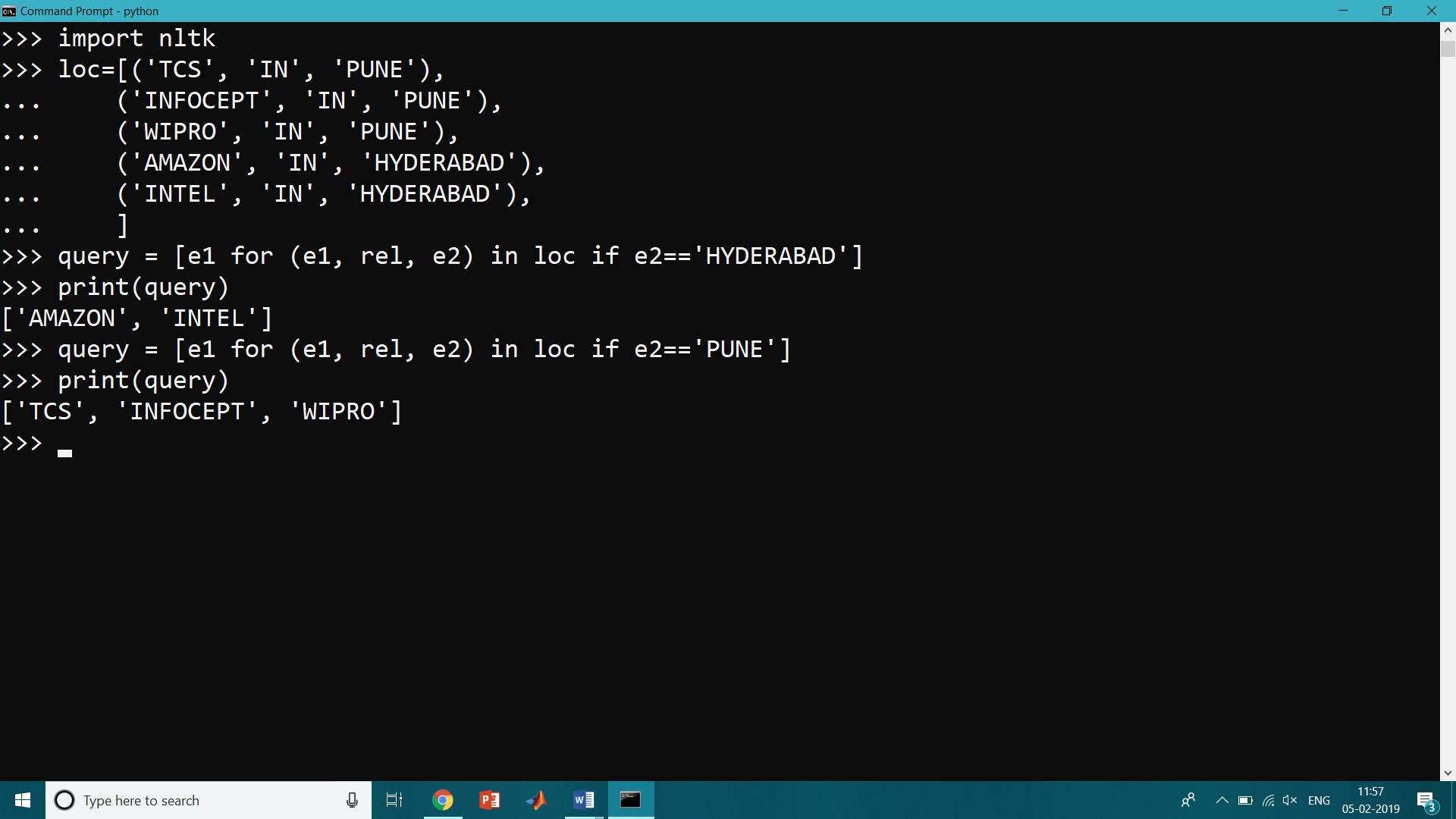
If this location data was stored in Python as a list of tuples (entity, relation, entity), then the question “Which organizations operate in HYDERABAD?” could be given as follows:
>>> import nltk
>>> loc=[('TCS', 'IN', 'PUNE'),
... ('INFOCEPT', 'IN', 'PUNE'),
... ('WIPRO', 'IN', 'PUNE'),
... ('AMAZON', 'IN', 'HYDERABAD'),
... ('INTEL', 'IN', 'HYDERABAD'),
... ]
>>> query = [e1 for (e1, rel, e2) in loc if e2=='HYDERABAD']
>>> print(query)
['AMAZON', 'INTEL']
>>> query = [e1 for (e1, rel, e2) in loc if e2=='PUNE']
>>> print(query)
['TCS', 'INFOCEPT', 'WIPRO']
Information Extraction has many applications, including business intelligence, resume harvesting, media analysis, sentiment detecti on, patent search, and email scanning. A particularly important area of current research involves the attempt to extract structured data out of electronically-available scientific literature, especially in the domain of biology and medicine.
Information Extraction Architecture
Following figure shows the architecture for Information extraction system.
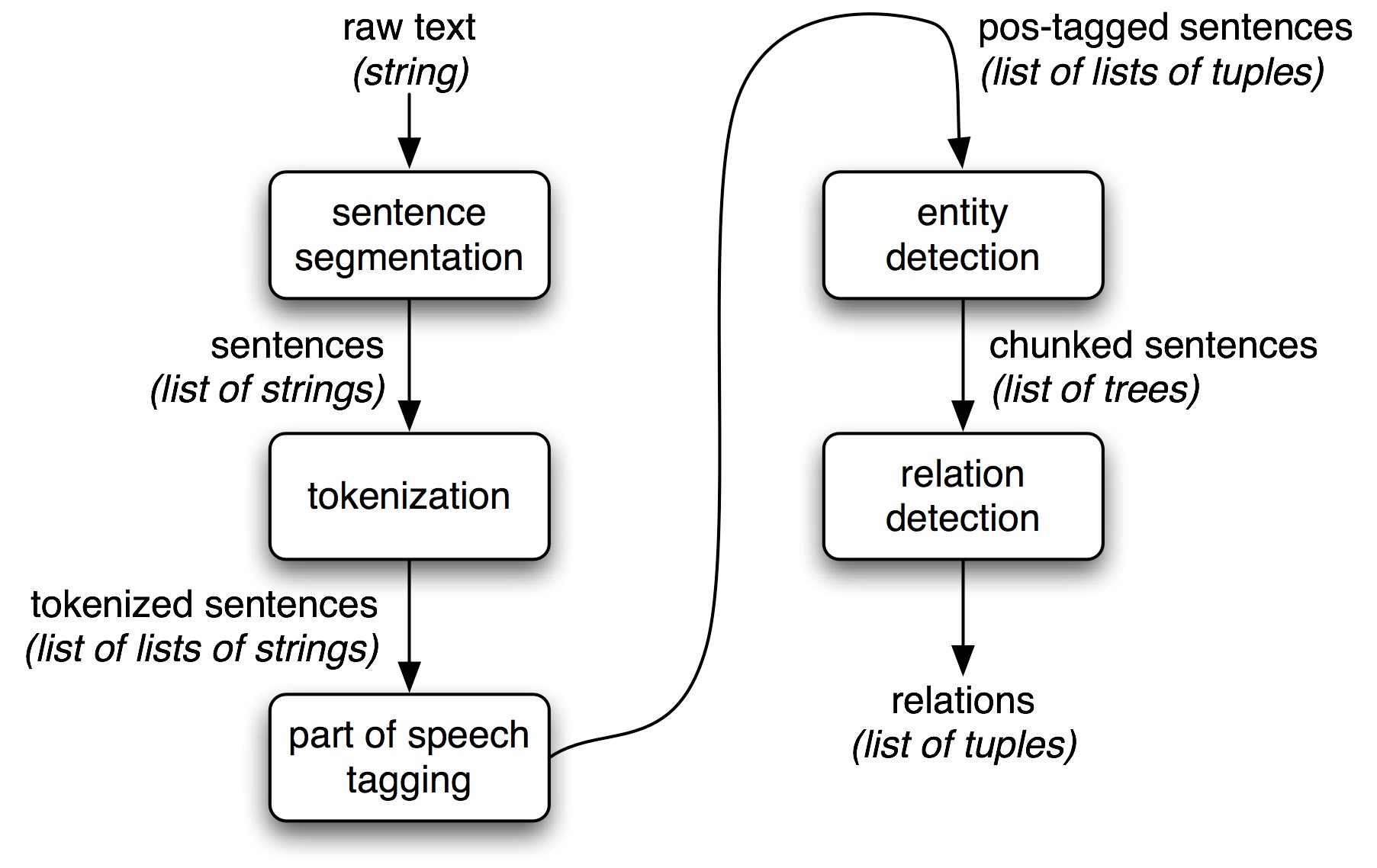
The above system takes the raw text of a document as an input, and produces a list of (entity, relation, entity) tuples as its output. For example, given a document that indicates that the company INTEL is in HYDERABAD it might generate the tuple ([ORG: ‘INTEL’] ‘in’ [LOC: ‘ HYDERABAD’]). The steps in the information extraction system is as follows.
STEP 1: The raw text of the document is split into sentences using a sentence segmentation.
STEP 2: Each sentence is further subdivided into words using a tokenization.
STEP 3: Each sentence is tagged with part-of-speech tags, which will prove very helpful in the next step, named entity detection.
STEP 4: In this step, we search for mentions of potentially interesting entities in each sentence.
STEP 5: we use relation detection to search for likely relations between different entities in the text.
Chunking
The basic technique that we use for entity detection is chunking which segments and labels multi-token sequences.
In the following figure shows the Segmentation and Labelling at both the Token and Chunk Levels, the smaller boxes in it show the word-level tokenization and part-of-speech tagging, while the large boxes show higher-level chunking. Each of these larger boxes is called a chunk. Like tokenization, which omits whitespace, chunking usually selects a subset of the tokens. Also, like tokenization, the pieces produced by a chunker do not overlap in the source text.
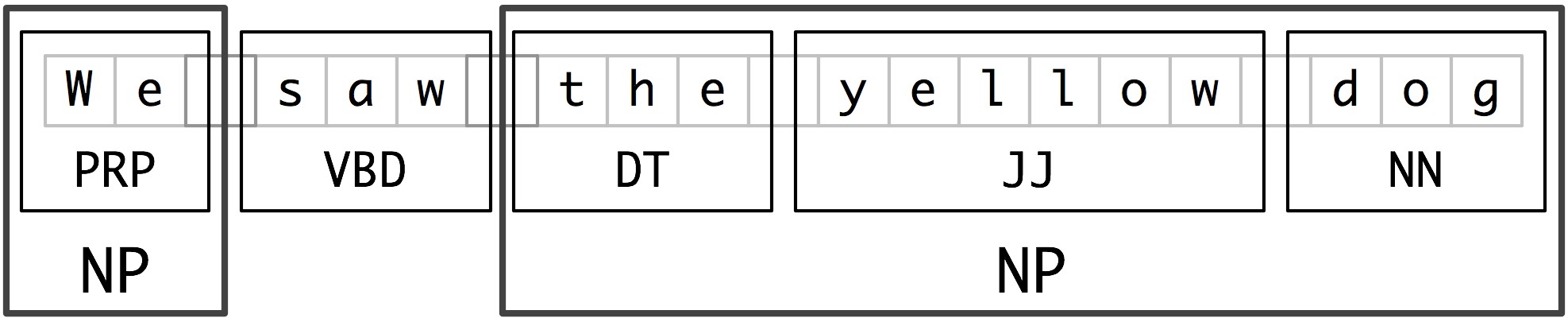
Noun Phrase Chunking
In the noun phrase chunking, or NP-chunking, we will search for chunks corresponding to individual noun phrases. For example, here is some Wall Street Journal text with NP-chunks marked using brackets:
[ The/DT market/NN ] for/IN [ system-management/NN software/NN ] for/IN [ Digital/NNP ] [ 's/POS hardware/NN ] is/VBZ fragmented/JJ enough/RB that/IN [ a/DT giant/NN ] such/JJ as/IN [ Computer/NNP Associates/NNPS ] should/MD do/VB well/RB there/RB ./.
NP-chunks are often smaller pieces than complete noun phrases.
One of the most useful sources of information for NP-chunking is part-of-speech tags.
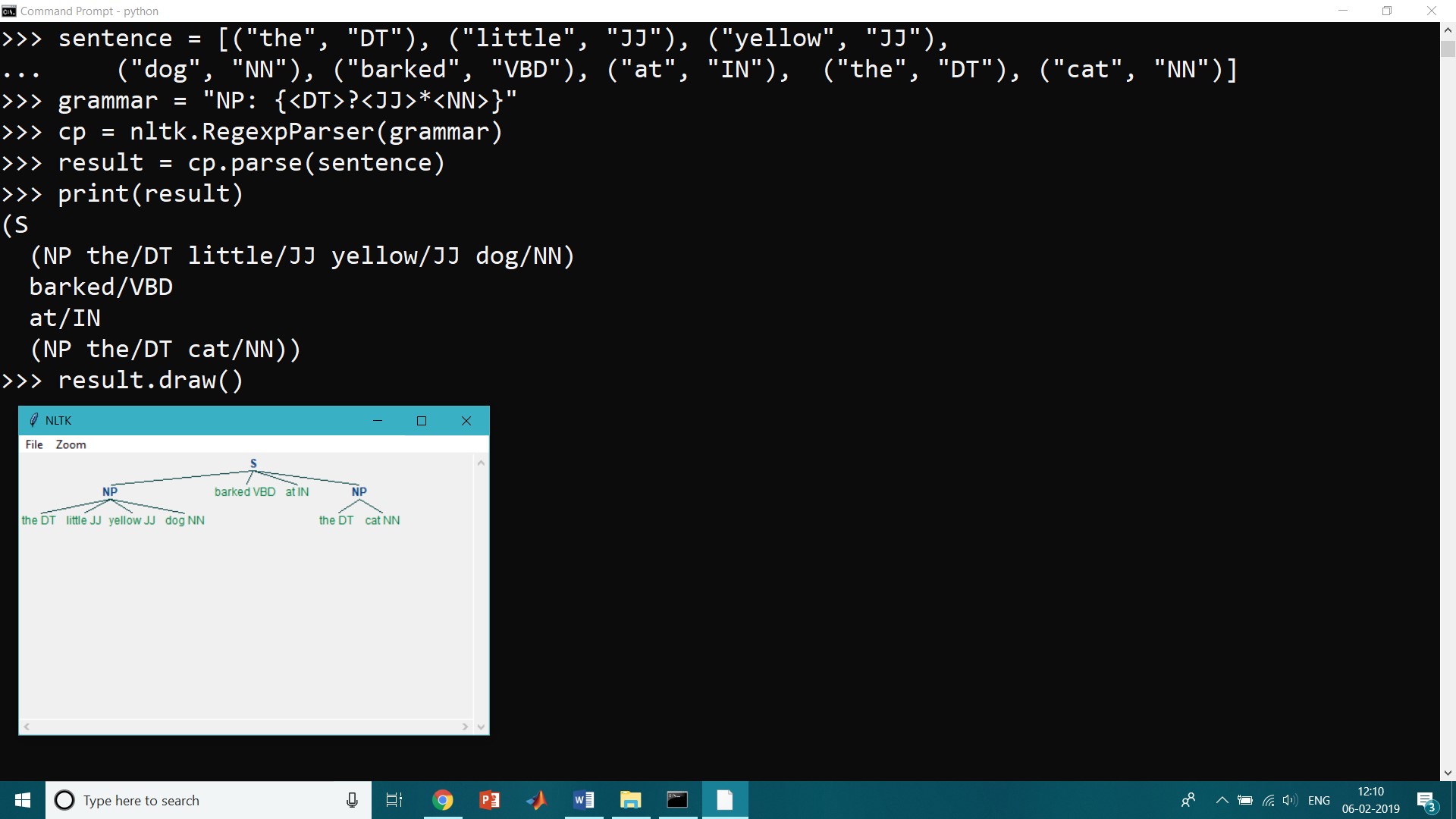
This is one of the inspirations for performing part-of-speech tagging in our information extraction system. We determine this approach using an example sentence. In order to create an NP-chunker, we will first define a chunk grammar, consisting of rules that indicate how sentences should be chunked. In this case, we will define a simple grammar with a single regular-expression rule. This rule says that an NP chunk should be formed whenever the chunker finds an optional determiner (DT) followed by any number of adjectives (JJ) and then a noun (NN). Using this grammar, we create a chunk parser , and test it on our example sentence. The result is a tree, which we can either print, or display graphically.
>>> sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),
... ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
>>> grammar = "NP: {<DT>?<JJ>*<NN>}"
>>> cp = nltk.RegexpParser(grammar)
>>> result = cp.parse(sentence)
>>> print(result)
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
>>> result.draw()
Chunking with Regular Expressions
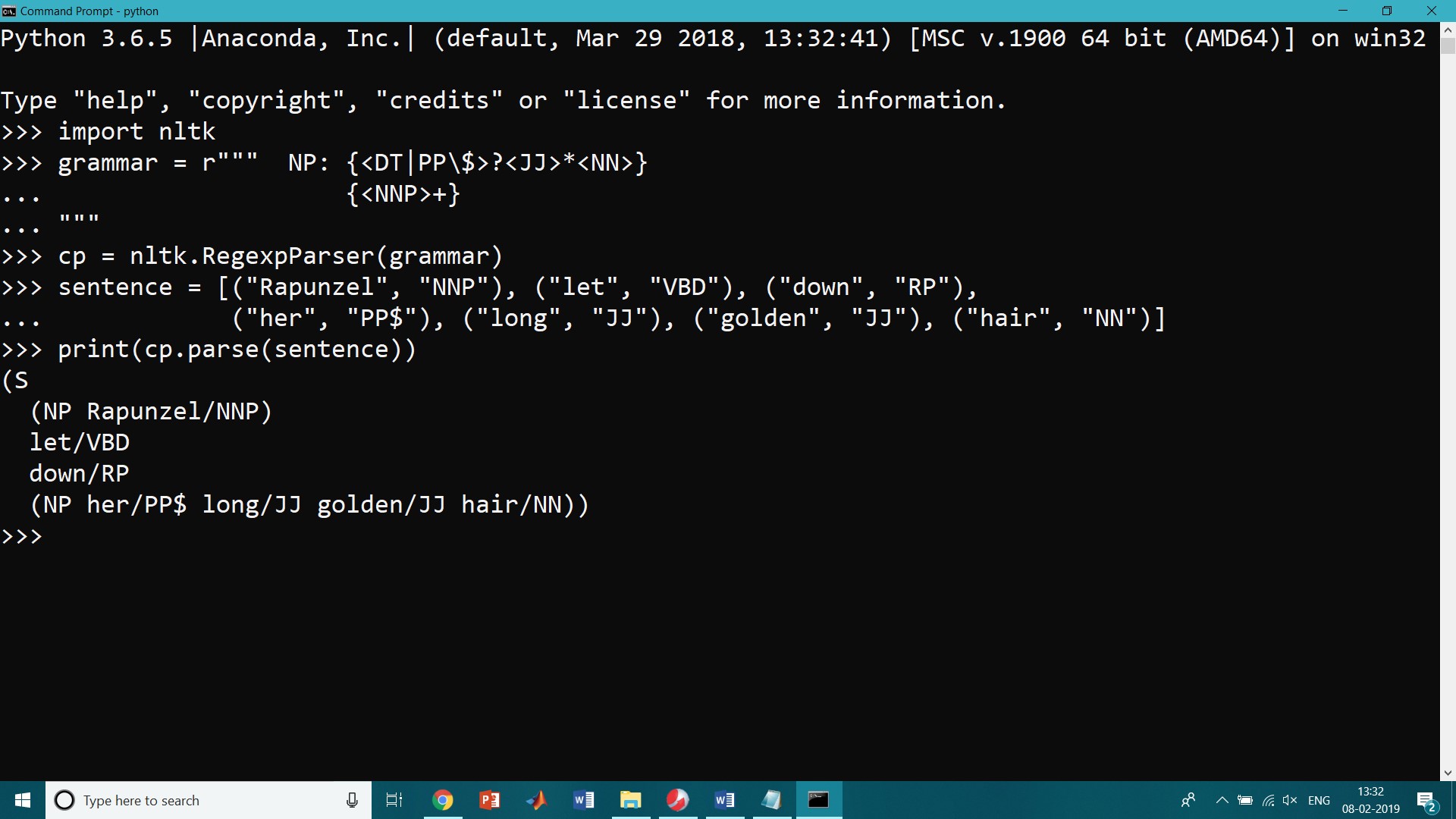
To find the chunk structure for a given sentence, the Regexp Parser chunker starts with a flat structure in which no tokens are chunked. The chunking rules applied in turn, successively updating the chunk structure. Once all the rules have been invoked, the resulting chunk structure is returned. Following simple chunk grammar consisting of two rules. The first rule matches an optional determiner or possessive pronoun, zero or more adjectives, then a noun. The second rule matches one or more proper nouns. We also define an example sentence to be chunked and run the chunker on this input.
>>> import nltk
>>> grammar = r""" NP: {<DT|PP\$>?<JJ>*<NN>}
... {<NNP>+}
... """
>>> cp = nltk.RegexpParser(grammar)
>>> sentence = [("Rapunzel", "NNP"), ("let", "VBD"), ("down", "RP"),
... ("her", "PP$"), ("long", "JJ"), ("golden", "JJ"), ("hair", "NN")]
>>> print(cp.parse(sentence))
OUTPUT:
(S (NP Rapunzel/NNP) let/VBD down/RP (NP her/PP$ long/JJ golden/JJ hair/NN))
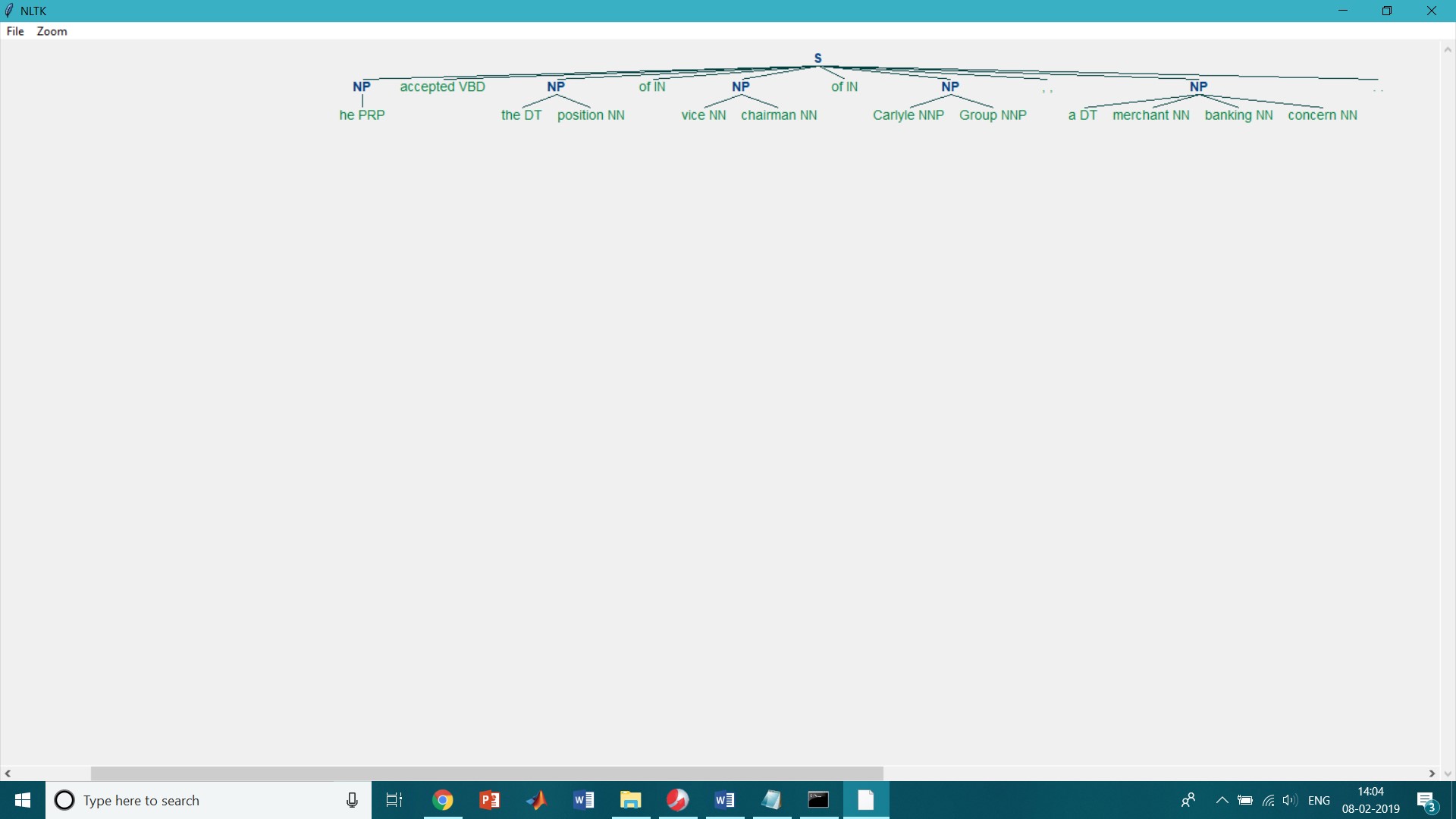
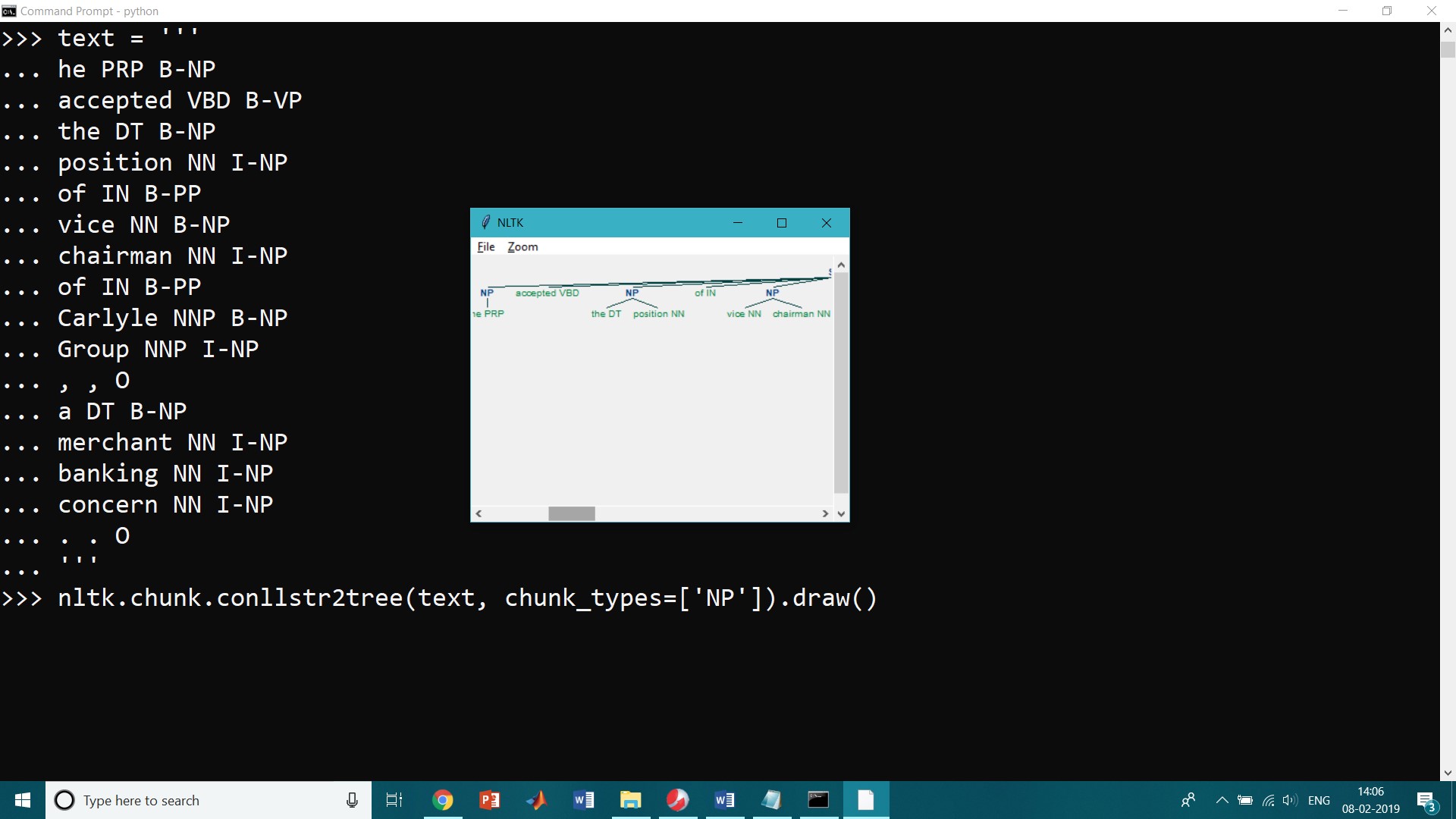
chunk.conllstr2tree() Function:
A conversion function chunk.conllstr2tree() is used to builds a tree representation from one of these multi-line strings. Moreover, it permits us to choose any subset of the three chunk types to use, here just for NP chunks:
>>> text = ''' ... he PRP B-NP ... accepted VBD B-VP ... the DT B-NP ... position NN I-NP ... of IN B-PP ... vice NN B-NP ... chairman NN I-NP ... of IN B-PP ... Carlyle NNP B-NP ... Group NNP I-NP ... , , O ... a DT B-NP ... merchant NN I-NP ... banking NN I-NP ... concern NN I-NP ... . . O ... ''' >>> nltk.chunk.conllstr2tree(text, chunk_types=['NP']).draw()